Over the last 20+ years I've designed and compiled a large number of databases, of which the Earth Systems Database (originally Paul's Vertebrate Database) used for my thesis in Chicago is probably the largest and most comprehensive. On the following pages the aim is to provide a basic understanding of database design and especially the problems involved in dealing with geological and ecological data. I've also included a series of pages that show in more detail my own databases, which will give users an idea of their content but also design ideas.
More detailed information will be added to this part of the web site as time allows. In the meantime more information can be found in my PhD thesis or in Markwick & Lupia (2002).
More detailed information will be added to this part of the web site as time allows. In the meantime more information can be found in my PhD thesis or in Markwick & Lupia (2002).
Database design
Databases serve a variety of functions, from simple means of data storage to analytical research tools. Consequently database design must take these different requirements into account. Most scientific researchers need both functions, but usually for specific (and limited) amounts and types of information (related to a defined research problem or series of experiments). The rapid expansion of desktop computing power has greatly facilitated database design.

|
LEFT: Different types of database: the simple Flat File Database (basically analogous to a card index system), which is a single table of information; Relational Databases in which multiple tables of data are linked (related) such that queries can be asked of one or more in relation to data in another; GIS, which are relational databases accessable through maps (see Markwick & Lupia 2002) .
|
For the Earth Sciences location in space and time is a crucial element of the data, and this is why desktop Geographic Information Systems (GIS) have become so widespread in the Geological community, as they place relational databases in the context of maps (GIS is used throughout all aspects of my research, presented in this site).
|
RIGHT: The basic design of many palaeontological databases comprises three principle tables: Locality (in time and space and which can include information pertinent to the spatial and temporal position of the fossil in question); Taxonomy (the taxonomic description of the fossil); Occurrence (providing the link between location and fossil name, which will be true for an occurrence of the fossil concerned). See Markwick & Lupia 2002 for further discussion .
|
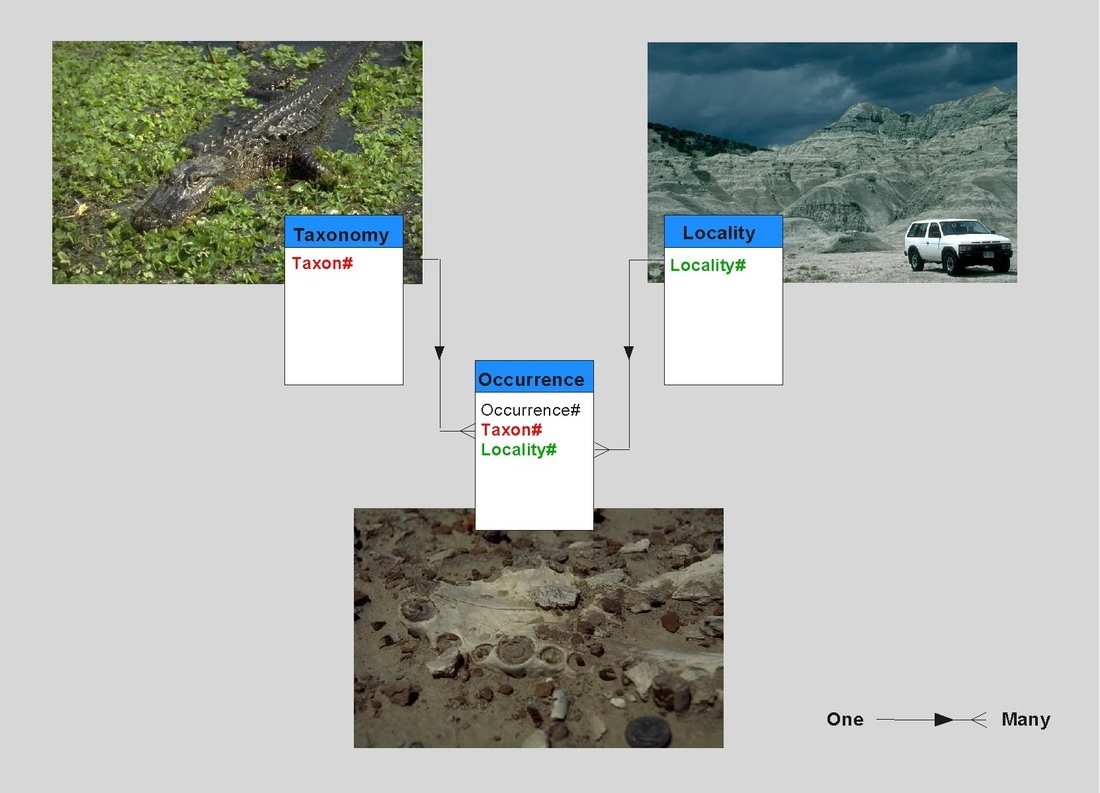
|
The principle problem in geology is that the data is extremely heterogeous, and this creates many problems for database designers, and especially the unwarey database user who may naively assume that all data in a database is equal. This is dealt with in more depth in the data section. The deisgn must provide flexibiliy to account for this heterogeneity and in my databases this is accomplished with qualifying fields (attributes) that provide an indication of the grain (resolution) and condidence of data. In addition the Earth System Database includes numerous lookup tables (libraries) that make changes to the database easier to permeate through the whole system (see my PhD thesis for more details Markwick, 1996)
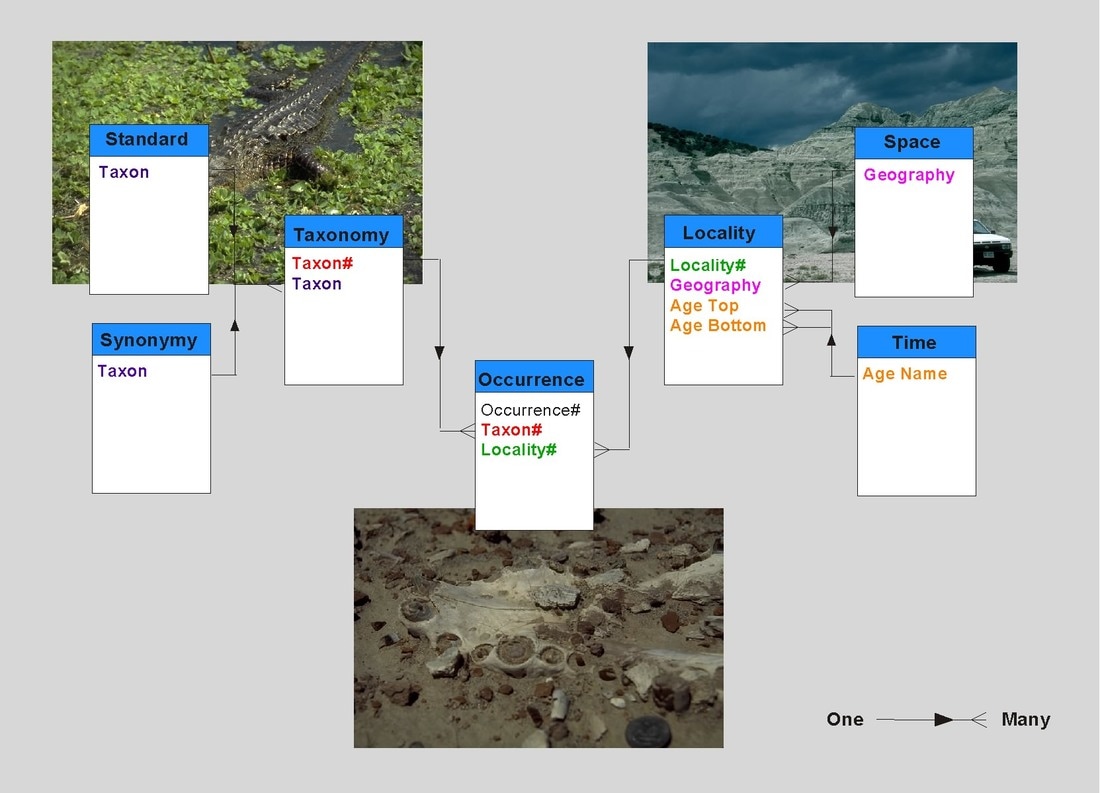
|
LEFT: To the basic database structure are added lookup tables that allow for additions and changes to be more efficiently entered into the database structure and then permeated throughout the whole system.
|
Data and how to deal with it
Computer databases provide an essential tool for investigating large-scale spatial and temporal problems in the Earth Sciences. But, although advances in both software and hardware have made the logistics of building a database much easier, fundamental problems remain concerning the representation and qualification of the data. In many ways databases have made the extraction of large datasets a little too easy, and the danger is that information is extracted without really understanding what the data actually represents. For example, a reported "Maastrichtian" locality in one place may not mean exactly the same thing as a "Maastrichtian" locality in another: one may represent a single channel sand with a vertebrate assemblage that represents almost an instant in geological time; another may be the composite fauna from a whole formation that spans the Maastrichtian; or, of course, the 'Maastrichtian' age assignment may just be wrong! Geological data are highly heterogeneous and databases must be designed to account for this, including variations in scale (grain, resolution), inconsistency in the data, and potential errors (inaccuracy).
These issues vary with the scope of the study (extent), the biological group, and the nature and scale-dependence of supplementary, non-biological, datasets (e.g. climate and ocean parameters). With the application of desktop geographic information systems (GIS) to global earth systems science, and the ability to efficiently integrate and query large, diverse datasets, the need to ensure robust qualification of data, especially scale, has become all the more essential.
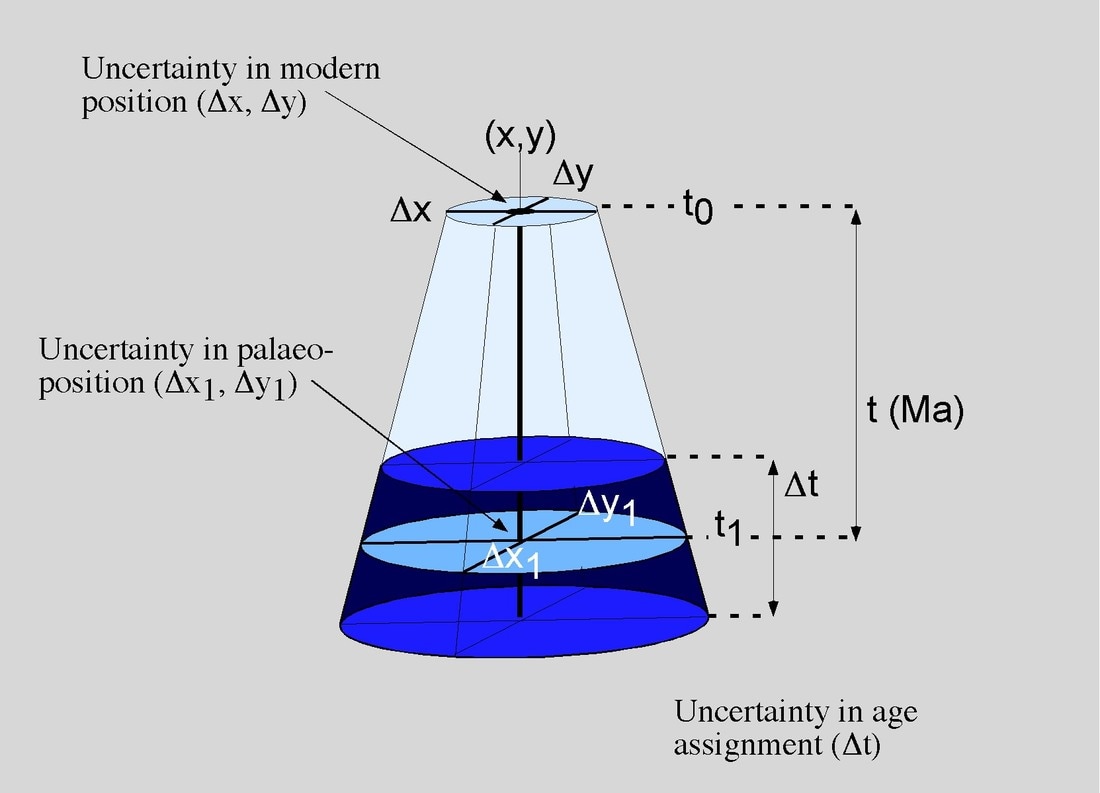
|
LEFT: The uncertainty in spatial and temporal position of a geological record also changes with the geological time (Markwick & Lupia 2002) .
|
In compiling my own databases much of the time has been spent including information that was solely use to constrain the data I was actually interested in. The inclusion of specimen information provided a check on how reliable a taxonomic allocation might be; age dates were always qualified to reflect their provenance and nature. This is outlined in my thesis and summarised in Markwick & Lupia (2002) to which anyone interested in this issue should refer. In Industry qualifying data is all the more critical since it can have major financial reprecussions, and so consequently I spend much of my professional time deriving methods for dealing with uncertainty and heterogeneity using GIS-based models.
The important lesson is to ensure that all data in a database is checked for errors during entry: this is simple in GIS, where carefully designed queries can easily be made to highligh errors such as incorrect location. "Uncertainties" need to be highlighted, either by a simple qualifying code that can allow 'good' or 'poor' data to be differentiated, or by a comments field that can be used by the compiler to draw attention to any problems. As such data entry is not something that should be done by inexperienced staff ("on the cheap") but by people familar with the data. Once the data is entered it is invariably very difficult, and certainly time-consuming, to go back and re-check everything.
The Earth Systems Database (formerly the Vertebrate Database)
(On my original site this section included related pages describing in (nauseating) detail each table in the database. I have removed this for the sake of sanity, but if you would like further information please contact me).
The Earth Systems Database was originally designed as a means of storing and analysing floral and vertebrate data used in my PhD thesis. Today it contains additional geological information used in my GIS-based databases, as well as modern climate, sedimentological and ecological data used in constraining and understanding the position of climate proxies in climate space.
The principle structure of the database is shown below. For each of the major elements there is a web page outlining the basic information included (see menu, left). Examples of the principle data entry forms (e.g. Locality, Taxonomy, etc.) are included as thumbnail images that can be clicked on to access a more legible version of the image. For the time being I've only included a cursory outline of what each part of the database contains. For more information researchers are directed to my PhD thesis, which includes a detailed description of the database and all the fields it contains.
The Earth Systems Database was originally designed as a means of storing and analysing floral and vertebrate data used in my PhD thesis. Today it contains additional geological information used in my GIS-based databases, as well as modern climate, sedimentological and ecological data used in constraining and understanding the position of climate proxies in climate space.
The principle structure of the database is shown below. For each of the major elements there is a web page outlining the basic information included (see menu, left). Examples of the principle data entry forms (e.g. Locality, Taxonomy, etc.) are included as thumbnail images that can be clicked on to access a more legible version of the image. For the time being I've only included a cursory outline of what each part of the database contains. For more information researchers are directed to my PhD thesis, which includes a detailed description of the database and all the fields it contains.
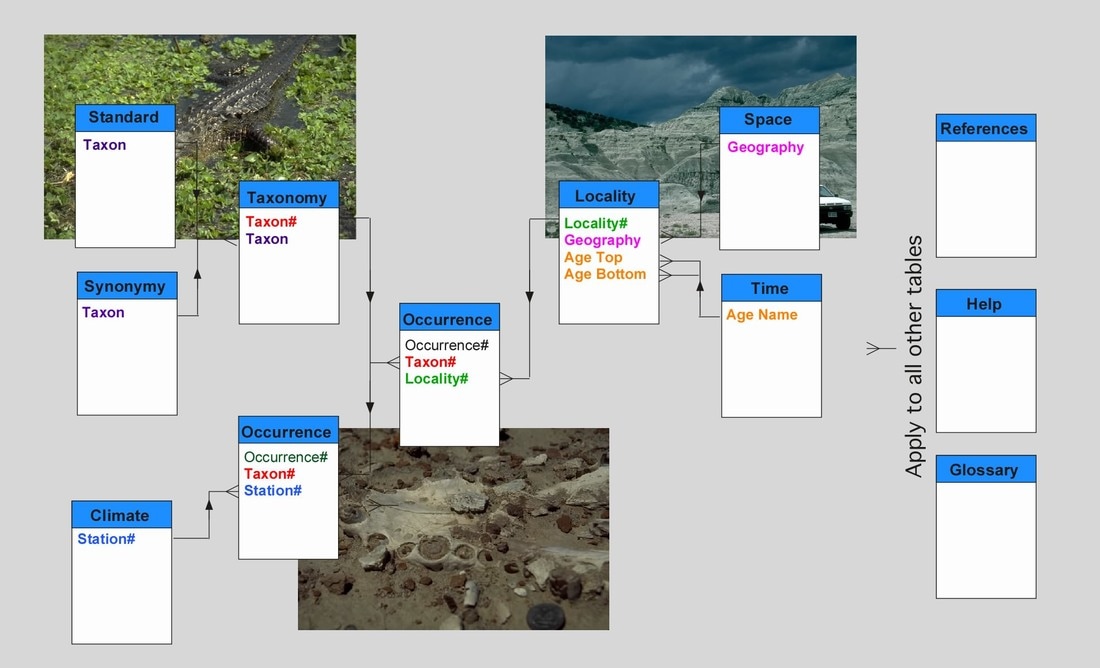
|
LEFT: The basic structure of the Earth Systems Database
|
Several general lessons about databases, especially databases of global extent are presented as follows (see also Markwick & Lupia, 2002):
- A database needs to be comprehensive enough to address the questions asked of it, but at the same time simple enough to be useable. A common problem is that databases, especially when designed by committee, tend to try and do too much, and as a consquence become unwieldly.
- Database Flexibility: because needs change, database structure needs to be so designed that additional information/tables/types of data can be added with the minimum of effort. A modular approach, with numerous lookup tables of different information seems to work most efficiently with data being changed only once in one table and then the results permeated throughout the whole.
- Attribution: - this is a data issue, but worth mentioning here; all data must be properly referenced and qualified. Once data is stored within a database it tends to look similar (in terms of it's provenance, reliability etc.) and so compilers must include distinctions at the time of entry.
- Each table must have a unique identifier that can then be used to link records between tables. It is adviseable that this does not incorporate any meaning, for the reason that such meaning may change as more information is accumulated. A simple sequential number works well in the databases I have designed.